计算机系统结构学习笔记
第一章计算机系统结构概念
函数栈调用过程:函数调用过程中函数栈详解-CSDN博客
系统结构自2004年开始从单纯依靠指令级并行转向开发线程级并行和数据级并行
计算机系统的层次结构

L1:是微指令集编写的微程序直接由硬件和固件实现
L2:机器指令集编写的程序在L1级上的微程序进行解释执行

L1-L3级是用解释的方法实现的,L4-L6是用翻译的方法实现的

计算机组成是计算机系统结构的逻辑实现
计算机实现是计算机系统结构的物理实现
计算机系统结构的分类:
- 冯氏分类法:用系统的最大并行度分类,并行度:系统在单位时间内能够处理的最大二进制位数
- Flynn分类法:按照指令流和数据流的多倍性进行分类
- 指令流:计算机执行的指令序列
- 数据流:由指令流调用的数据序列
- 多倍性:在系统受限的部件上,同时处于同一执行阶段的指令或数据的最大数目
定量分析技术:
以经常性事件为重点。在计算机系统的设计中,对经常发生的情况,赋予它优先的处理权和资源使用权,以得到更多的总体上的改进。
Amdahl定律:加快某部件执行速度所能获得的系统性能加速比,受限于该部件的执行时间占系统中总执行时间的百分比。(那个部件执行时间越长,优化它越有用)


CPU性能公式

最重点需要关注IC以及CPI的含义,IC就是指令数量,CPI是每条指令执行的平均时钟周期数(执行指令的速度)
程序的局部性原理。程序在执行时所访问地址的分布不是随机的,而是相对地簇聚。
计算机系统的性能评测:
- 执行时间和吞吐率
- 基准测试程序(benchmark)
冯·诺依曼结构
- 输入输出设备、控制器、运算器、存储器
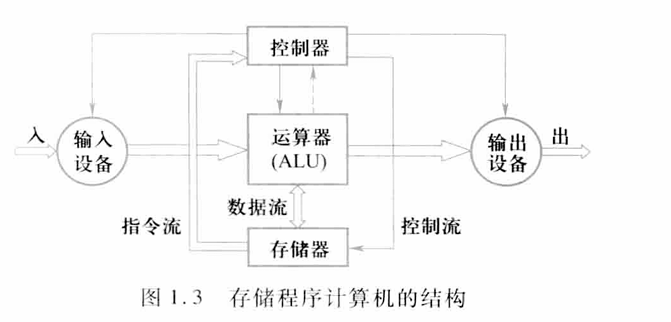
- 存储程序原理的基本点是指令驱动
DMA方式:
- 没传送完一批数据就要中断CPU一次,为了使CPU进一步摆脱用于管理、控制I/O系统的沉重负担,这就出现了I/O处理机方式
并行处理技术:
- 再不同级别采用并行技术,如微操作级、指令级、线程级、进程级、任务级别,在这方面先后出现了向量计算机、阵列处理机、多处理机等并行处理计算机
指令集的发展:
- 线代计算机的指令仍是由操作码和地址码两部分组成
- CISC、RISC
1.4.2 软件对系统结构的影响
系列机:同一个厂商生产的具有相同系统结构,但具有不同组成和实现的一系列不同型号的计算机、具有相同的指令集
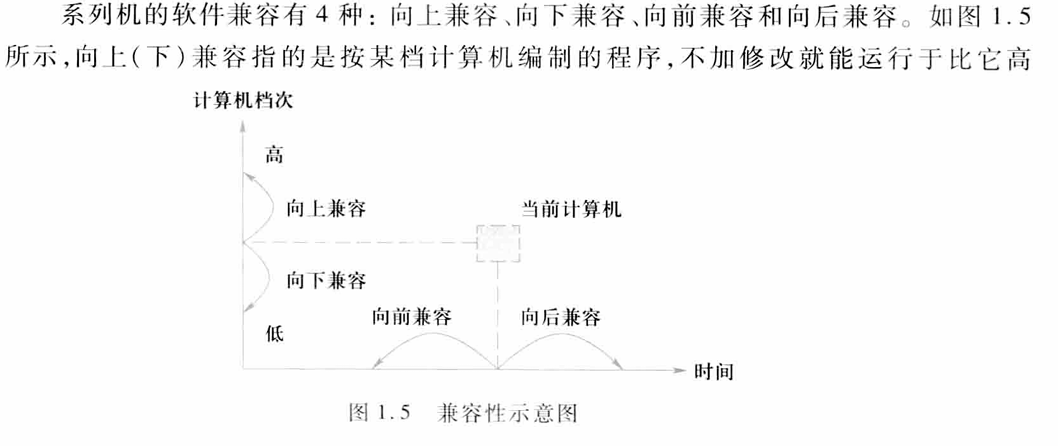
兼容机:不同厂商生产的具有相同系统结构的的计算机
模拟:软件的方法在一台计算机上实现另一台计算机的指令集,采用解释的方法
仿真:用一台现有的计算机上的微程序去解释实现另一台计算机的指令集
1.4.4 应用对系统结构的影响
- 应用需求是促使计算机系统结构发展的最根本的动力
1.5.1 并行性的概念
- 处理数据的角度的并行性等级:
- 1.字串位串:每次只对一个字的一位进行处理,无并行性
- 2.字串位并:同时对一个字的全部位进行处理,不同字之间是串行的
- 3.字并位串:同时对许多字的同一位进行处理
- 4.全并行:同时对许多字的全部位和部分位进行处理
- 执行程序的角度的并行性等级
- 1.指令内部并行:单条指令中各微操作之间的并行
- 2.指令级并行(ILP):并行执行两条或两条以上的指令
- 3.线程级并行(TLP):并行两个或两个以上的线程
- 4.任务级或过程级并行:并行执行两个或两个以上过程或作业(程序段),以子程序或进程为调度单元
- 5.作业或程序级并行并行执行两个或两个以上的作业或程序
1.5.2 提高并行性的技术途径
- 1.时间重叠(部件功能专用化):让多个处理过程在时间上相互错开,轮流重叠地使用同一套硬件设备的各个部分,加快硬件周转
- 2.资源重复:可以在单处理机中重复设置多个运算部件或处理部件,也可以重复设置多个处理机,构成多处理机系统
- 3.资源共享:多个任务按一定顺序轮流使用同一套硬件设备
第二章计算机指令集结构
2.1 指令级结构的分类
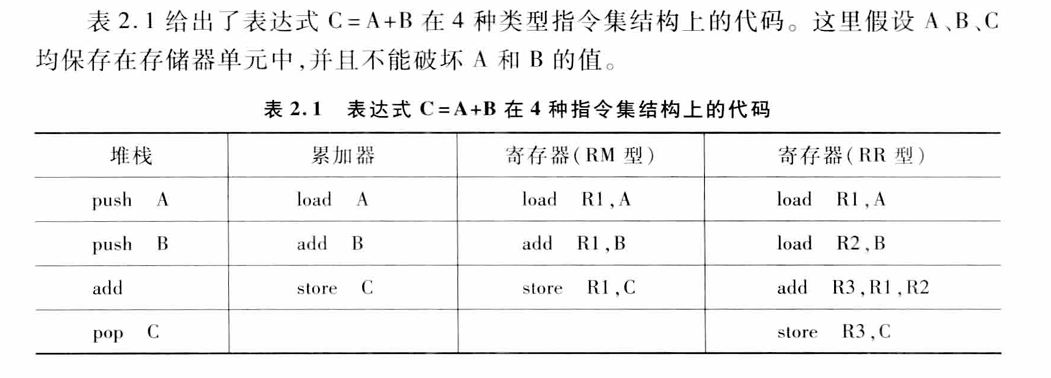
堆栈结构中操作数都是隐式的,只能通过push/pop指令访问存储器
在累加器结构中,一个操作数是隐式的,即累加器,另一个操作数则是显示给出
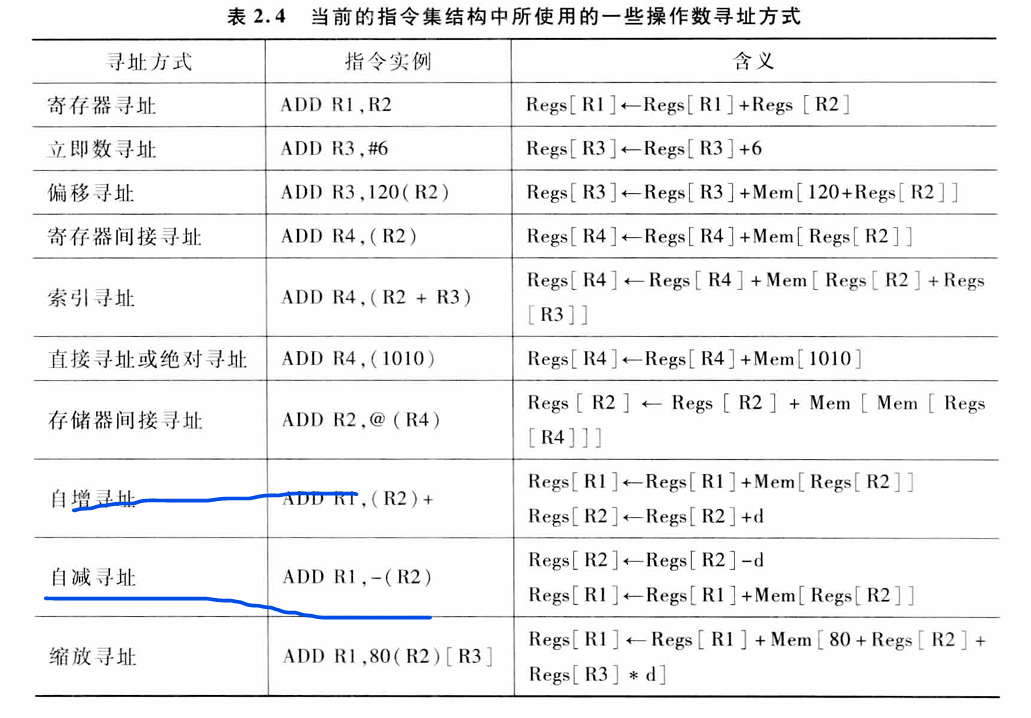
2.2 寻址方式
2.3 指令集结构的功能设计
对指令集的要求是完整性、规整性、高效率和兼容性

CISC是增强指令功能,把越来越多的功能交给硬件来实现,并且指令的数量也是越来越多;RISC尽可能把指令简单化,不仅指令条数少,指令的功能也比较简单
2.3.1 CISC指令集结构的功能设计
1、面相目标程序增强指令功能
- 增强运算型指令的功能
- 增强数据传送指令的功能:多种程序控制指令
- 增强程序控制指令的功能
从上述3个方面来改进目标程序可能获得较好的结果,但增加了硬件的成本和复杂度。对频繁使用的子程序和指令串,用较强功能的指令取而代之才划得来
2、面向高级语言的优化实现来改进指令集
- 增强对高级语言和编译器的支持:对源程序中各种高级语言语句的使用频度进行统计与分析,找出高频,执行时间长的语句
- 高级语言计算机
3、面向操作系统的优化实现改进指令集
指令集对操作系统的支持主要有:
- 处理机工作状态和访问方式的切换
- 进程的管理和切换
- 存储管理和信息保护
- 进程的同步于互斥,信号灯的管理
2.3.2 RISC指令集结构的功能设计
设计RISC计算机原则遵循
- 1、指令条数少而简单
- 2、采用简单而又统一的指令格式
- 3、指令的执行在单个机器周期内完成(采用流水线机制后)
- 4、只有load和store指令才能访问存储器,其他指令的操作都是在寄存器之后执行,即采用load-store结构
- 5、大多数指令都采用硬连逻辑来实现
- 6、强调优化编译器的作用,为高级语言程序生成优化的代码
- 7、充分利用流水技术来提高性能
2.4 操作数的类型和大小
数据表示是指计算机硬件能够直接识别、指令集可以直接调用的数据类型。如定点数、逻辑数、浮点数、字符和字符串
如何确定数据表示是系统结构设计者要解决的难题之一
表示操作数类型的方法有以下两种:
由指令中的操作码指定操作数的类型
给数据加上表示(tag)
2.5指令格式的设计
指令一般由两部分组成:操作码和地址码,哈夫曼编码来减少操作码的平均位数
2.6.1 MIPS的寄存器
- 32个64位通用寄存器(General-Purpose Registers,GPR,整数寄存器),R0的值永远是0,还有32个64位浮点数寄存器(Floating-Point Registers,FPR),既可以用来存放32个单精度浮点数(32位),也可以用来存放32个双精度浮点数(64位)
2.6.2 MIPS的数据表示
- 整数:8、16、32、64
- 浮点数:32、64
2.6.3 MIPS的数据寻址方式
- 按字节寻址
- 只有立即数寻址和偏移量寻址两种,但寄存器间接寻址通过把0作为偏移量来实现,16位的绝对寻址把R0作为基址寄存器来完成,所以实际有4种寻址
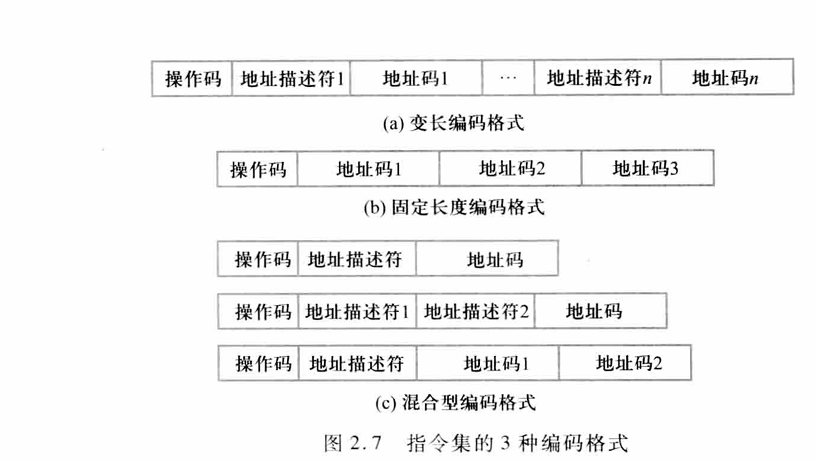
2.6.4 MIPS的指令格式
MIPS的寻址方式都是编码到操作码中的。MIPS按不同类型的指令设置不同的格式,共有3种格式,它们分别对应于I、R、J类指令
I类指令:包括所有的load和store指令,立即数指令,分支指令,寄存器跳转指令,寄存器链接跳转指令
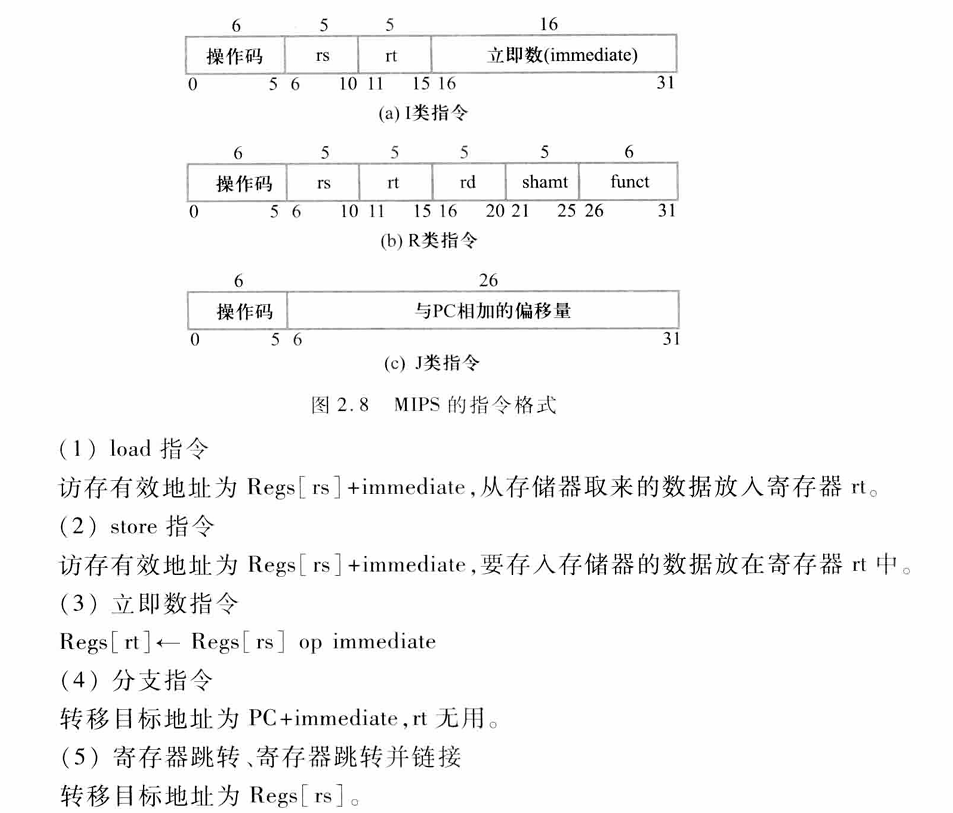
R类指令:包括ALU指令,专用寄存机读/写指令、move指令等
J类指令:包括跳转指令、跳转并连接指令、自陷指令与异常返回指令
2.6.5 MIPS的操作
MIPS指令可以分为4类:load和store、ALU操作、分支与跳转和浮点操作
单精度浮点数占用浮点寄存器的一般,单精度与双精度之间的转换必须显示地进行。浮点数的格式是IEEE 754



2.6.2 MIPS的控制指令
- 确定目标地址的方式有两种,一种是把指令中的26位偏移量左移2位(因为指令字长都是4B,所有的指令地址都是4字节对齐,所以目标地址总是4的倍数。左移2位相当于将26位偏移量乘以4,这样就能得到以字节为单位的实际目标地址),替换程序计数器的低28位。
- 另一种是由指令中指定的一个寄存器来给出转移目标地址,即间接跳转

第三章流水线技术pipelining
3.1.1 什么是流水线
- 指令流水线:应用于指令的解释执行过程
- 运算操作流水线:应用于运算的执行过程,也称为部件级流水线

3.1.2 流水线的分类
单功能流水线与多功能流水线
静态流水线与动态流水线P63
- 静态流水线:在同一时间内,多功能流水线中的隔断只能按同一种功能的连接方式工作。当要按另一种连接实现其他功能时,必须等原来连接方式处理,的所有任务都流出流水线之后,才能改变链接
- 动态流水线:在同一时间内,多功能流水线中的各段可以按照不同的方式链接,同时执行多种功能。它允许在某些段正在实现某种运算时,另一些段却在实现另一种运算
- 一般情况下,动态流水线的效率比静态流水线的高,但是动态流水线的控制要复杂得多,所以目前绝大多数的流水线是静态流水线
部件级流水线:把处理机的算术逻辑运算部件分段,使得各种类型的运算操作能够按流水方式进行。
处理机级流水线:把指令的解释执行过程按照流水方式处理
处理机间流水线(又称宏流水线):由两个或者两个两个以上的处理机串行连接起来,对统一数据流进行处理。
线性流水线:流水线的各段串行连接,没有反馈回路,每一个段最多只流过一次
非线性流水线:有反馈回路
顺序流水线与乱序流水线:乱序流水线的流入和流出顺序可以不同,允许后进入流水线的任务先完成
3.2.1 吞吐率
- 吞吐率是指在单位时间内流水线所完成任务数量或输出结果的数量
- 这一段内容主要讲流水线性能指标,包含各种吞吐率公式。P67-P70
3.2.2 加速比
- 完成同样一批任务,不使用流水线所用的时间与使用流水线所用的时间之比称为流水线的加速比(Speedup)

3.2.3 效率
- 流水线的效率是指流水线中的设备实际使用时间与整个运行时间的比值,即流水线设备的利用率,由于流水线有通过时间和排空时间,所以在连续完成n个任务的时间内,各段并不是满负荷地工作
3.2.5 流水线设计中的若干问题
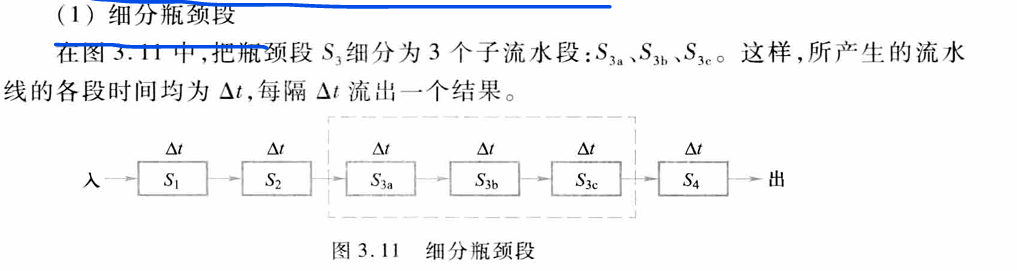
- 瓶颈问题:有的段处理时间比别的都长,这个段就成了瓶颈。因此,在设计流水线时要尽可能使各段时间相等。
- 解决的常用办法:细分瓶颈段、重复设置瓶颈段
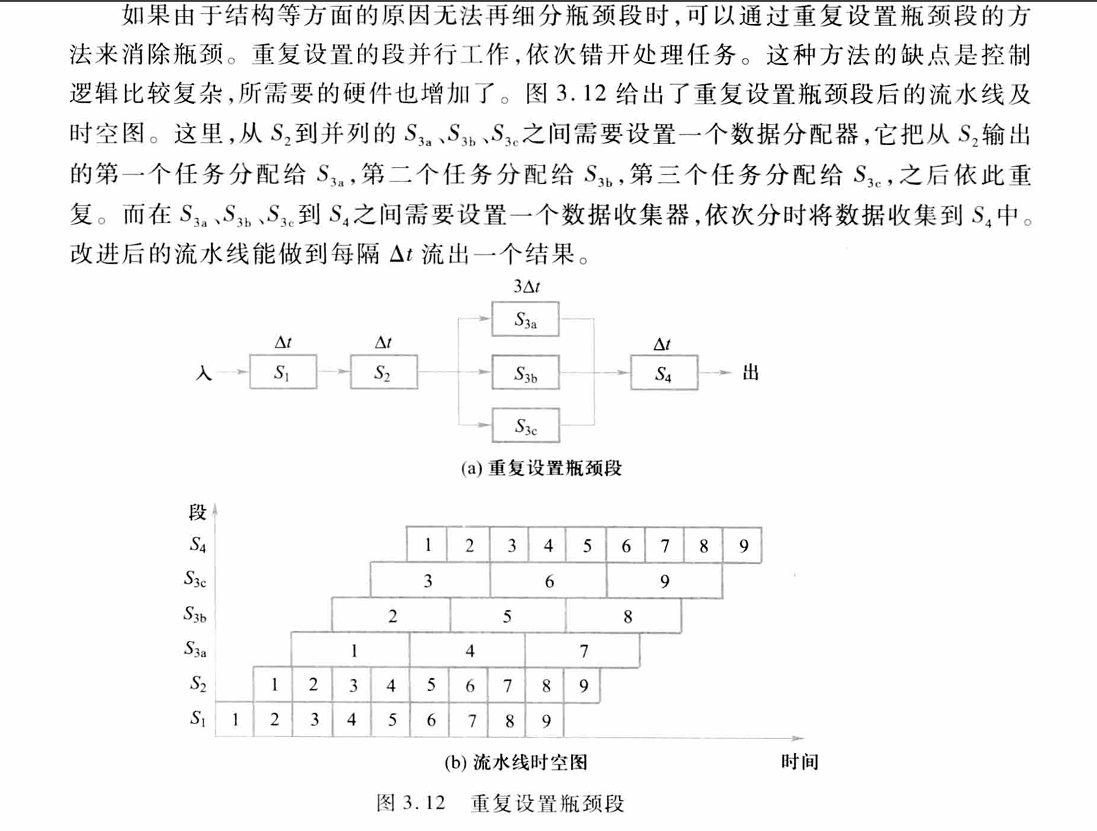
- 流水线的额外开销:流水寄存器延迟和时钟偏移开销

- 冲突问题:后面的计算或操作需要用到前面计算或操作的结果。所以需要相互等待,引起流水线的停顿
3.3 流水线的相关与冲突
3.1.1 一个经典的5段流水线、
取指令周期(IF)
根据PC指示的地址从存储器中取出指令并放入指令寄存器IR,同时PC+4(假设每条指令占4B)
指令译码/读寄存器周期(ID)
对指令进行译码,并用IR中的寄存器编号去访问通用寄存器组,读出所需的操作数
执行/有效地址计算周期(EX)

存储器访问/分支完成周期(MEM)

写回周期(WB)

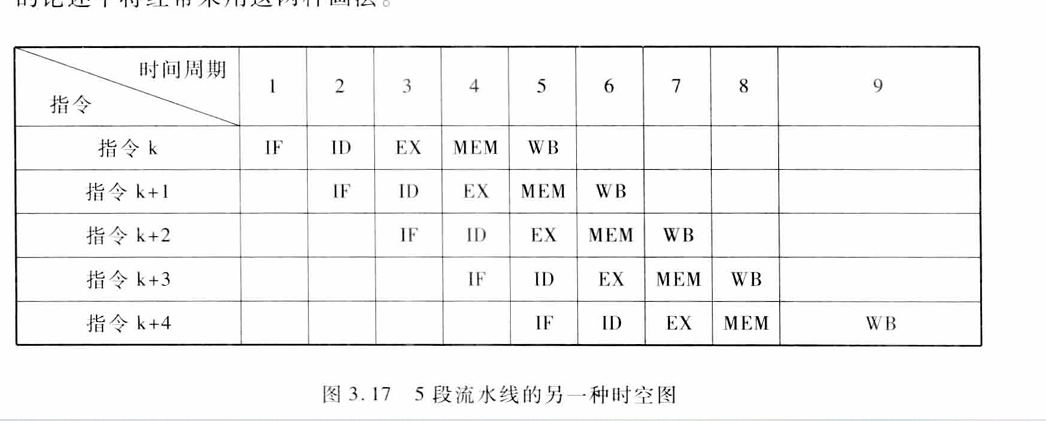
- 同一个时钟周期不能要求同一个功能段做两个不同的工作,比如不能要求ALU同时做有效地址计算和算术运算
3.3.2 相关和流水线冲突
相关就是指两条指令之间存在某冲依赖关系
数据相关(也称真数据相关)
名相关


控制相关

流水线冲突:
- 结构冲突:因硬件资源满足不了指令重叠执行的要求而发生的冲突
- 数据冲突:指令重叠执行时,因需要用到前面的执行结果而发生的冲突
- 写后读冲突(RAW)
- 写后写冲突(WAW)
- 读后写冲突(WAR)
- 控制冲突:流水线遇到分支指令和其他会改变PC值的指令所引起的冲突
发生冲突时需要用“气泡”(停顿x个时钟周期来推迟后面冲突的操作),或者将统一的Cache分成独立的指令Cache和数据Cache
为了减少停顿时间,为了减少停顿时间,可以采用一种称为定向(forwarding,也称为旁路或短路)的简单技术来解决写后读冲突。定向技术的关键思想是:在某条指令(如图3.22中所示的DADD指令)产生计算结果之前,其他指令(如图3.22中所示的DSUB和XOR指令)并不真正立即需要该计算结果,如果能够将该计算结果从其产生的地方(EX段和MEM段之间的流水寄存器)直接送到其他指令需要它的地方(ALU的入口),那么就可以避免停顿。
定向(forwarding,又称旁路或短路)是现代处理器流水线中的一种优化技术,用于解决数据冒险(特别是写后读冲突,RAW)。以下是它的含义和工作原理:
在流水线中,指令的执行是分阶段完成的。例如,在 5 级流水线中:
- IF(取指)
- ID(译码)
- EX(执行)
- MEM(访存)
- WB(写回)
假设有两条指令:
1 | DADD R1, R2, R3 # R1 = R2 + R3 |
写后读冲突的发生:
- 第 1 条指令的结果(
R1)只有在第 5 阶段(WB 写回阶段)才能写入寄存器文件。 - 但第 2 条指令在流水线中紧跟其后,**在第 3 阶段(EX 执行阶段)就需要使用
R1**。此时,R1的结果还没有写回寄存器文件,导致 RAW 冲突。
采用定向后:
数据流过程:
- DADD 指令执行到 EX 阶段:
- ALU 计算完成,结果存储在 EX/MEM 流水寄存器中。
- DSUB 指令到达 EX 阶段:
- 它需要
R1的值,而此时R1还没有写回寄存器文件。 - 定向技术会直接将
R1的结果从 EX/MEM 流水寄存器转发到 ALU 的输入,供 DSUB 使用。
- 它需要
依靠编译器解决数据冲突
对于无法用定向技术解决的数据冲突,可以通过在编译时让编译器重新组织指令顺序来消除冲突,这种技术成为“指令调度”或“流水线调度”。
对于控制冲突
处理分支指令最简单的方法是“冻结”(freeze)或者“排空”(fush)流水线。即一旦在流水线的译码段ID检测到分支指令,就暂停执行其后的所有指令,直到分支指令到达MEM段、确定出是否成功并计算出新的PC值为止。如果分支成功,则按照新的PC值取指令,如图3.29所示。在这种情况下,分支指令给流水线带来了3个时钟周期的延迟。这种方法的优点在于其简单性。
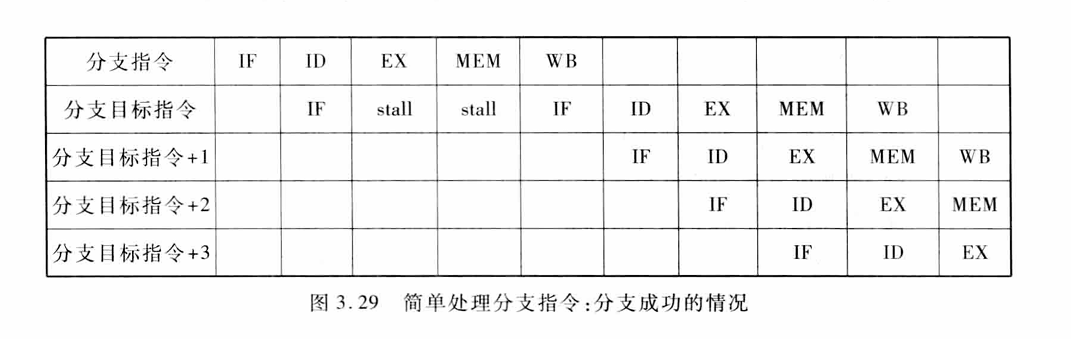
为了减少分支延迟,可以采取以下措施:
- 在流水线中尽早判断出分支转移是否成功
- 尽早计算出分支目标地址
这两种措施要同时采用,缺一不可
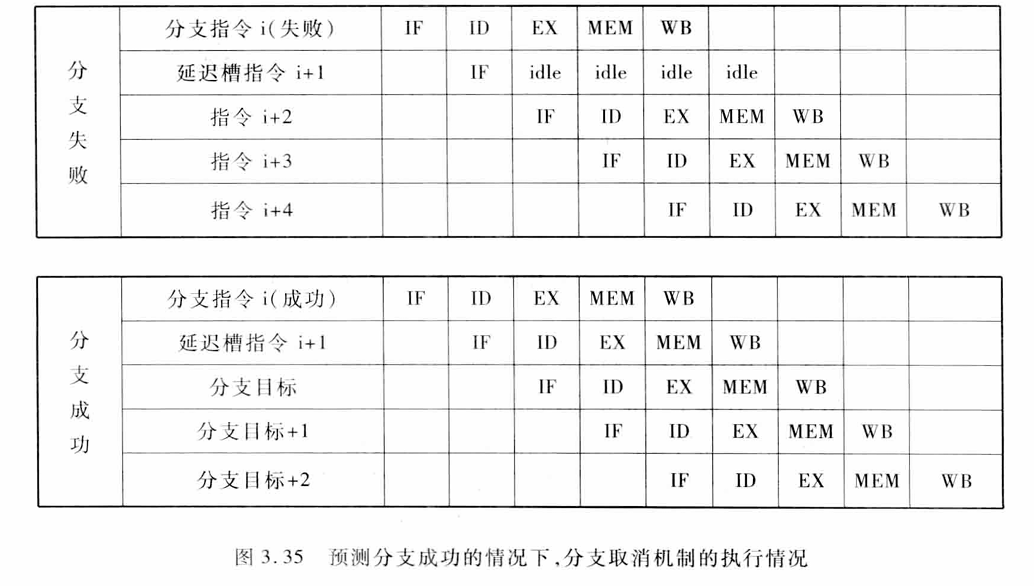
预测分支失败:预测分支失败就延失败的分支继续处理指令,成功则把分支指令之后取出的所有的指令转化为空操作,并按分支目标地址重新取指令执行
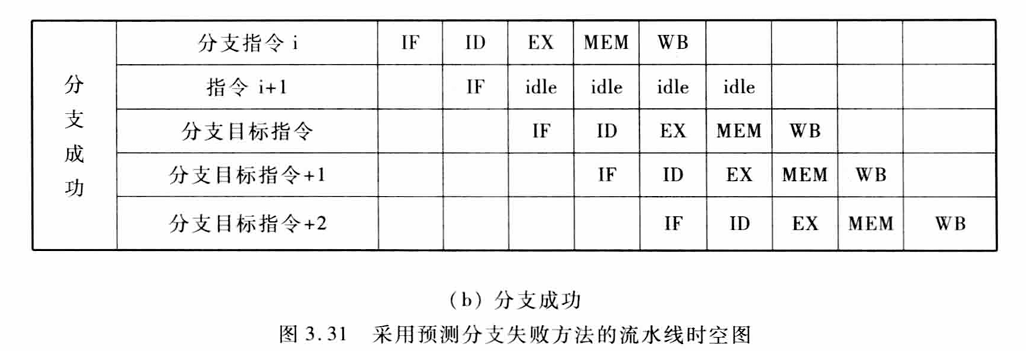
预测分支成功:这种方法按分支成功的假设进行处理。当流水线ID段检测到分支指令后,一旦计算出了分支目标地址,就开始从该目标地址取指令执行。
延迟分支:主要在分支指令的后面加上几条指令(如m条)然后把它们看成是一个整体,不管分支是否成功,都要按顺序执行这些指令。比如下面的例子:
未优化的分支:
1
2
3
4
5BEQ R1, R2, Label # 如果 R1 == R2,跳转
NOP # 空操作,占用延迟槽
ADD R3, R4, R5 # 后续指令
Label:
...使用延迟分支优化后:
1
2
3
4BEQ R1, R2, Label # 如果 R1 == R2,跳转
ADD R6, R7, R8 # 在延迟槽中插入有用指令
Label:
...延迟分支包括3种调度:从前调度、从后调度、从失败出调度
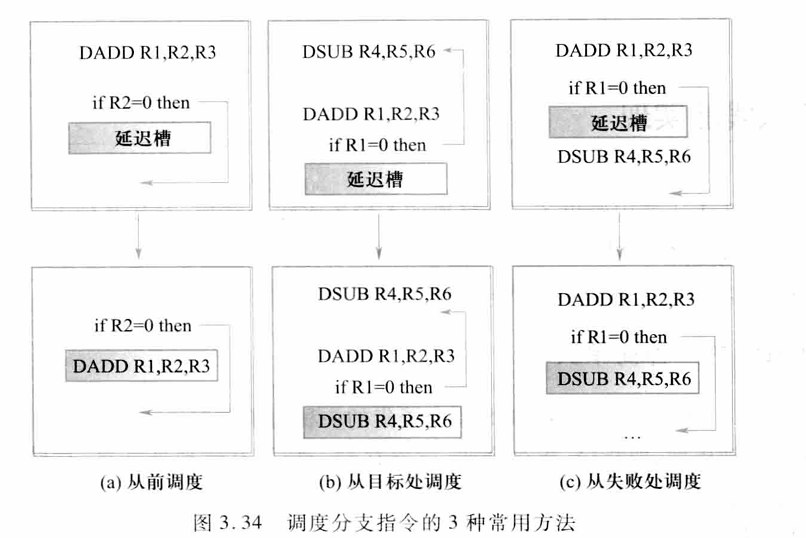
为了提高编译器在延迟槽中放入有用指令的能力,许多处理机采用了分支取消机制。在这种机制中,分支指令隐含了预测的分支执行方向。当分支的实际执行方向和事先所预测的一样时执行分支延迟槽中的指令,否则就将分支延迟槽中的指令转化成一个空操作。
3.4流水线的实现
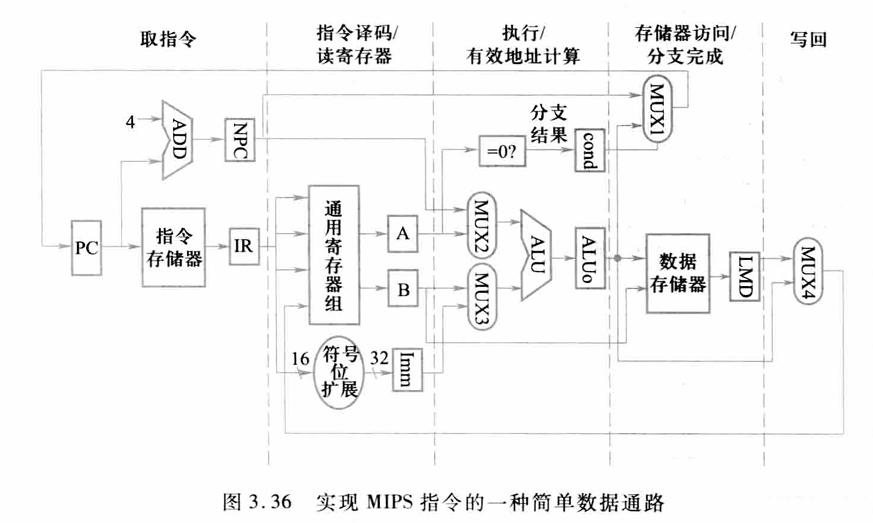
3.4.1 MIPS的一种简单实现
3.4.2 基本的MIPS流水线
设置了流水寄存器

流水寄存器有以下作用:

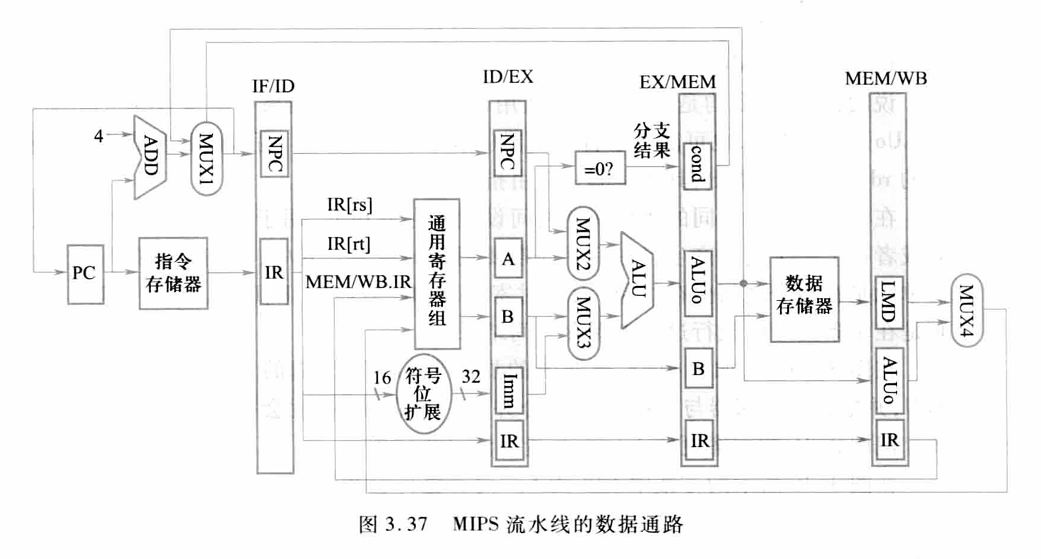
增加了向后传递的IR和从MEM/WB.IR回送到通用寄存器组的连接

将PC的修改移到IF段,以便PC能及时加4,为取下一条指令做好准备
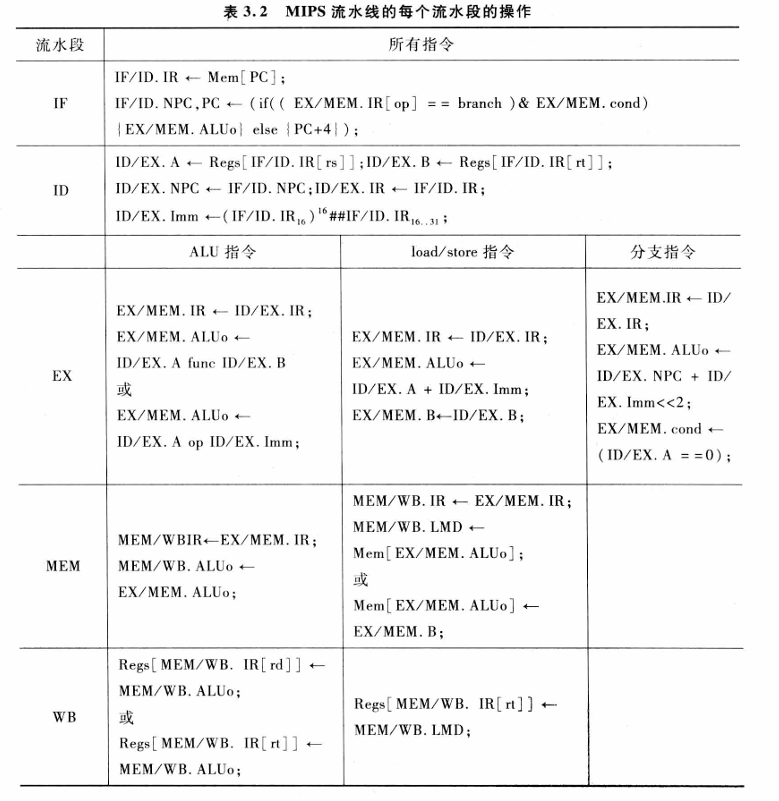
- IF(Instruction Fetch,指令取值阶段)
功能:从内存中取出指令,并计算下一条指令的地址。
具体操作
IF/ID.IR ← Mem[PC]:从内存中取出指令,存入流水线寄存器IF/ID.IR。IF/ID.NPC, PC ← (if ((EX/MEM.IR[op] == branch) & EX/MEM.cond) {PC+4})BEQ R1, R2, label ; 比较 R1 和 R2,如果相等跳转到 label 2: ADD R3, R4, R5 ; 否则执行 ADD 3: label: SUB R6, R7, R8; label 位置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
- 如果前一条指令是分支且条件成立,则更新PC为分支目标地址。
- 否则,将PC更新为下一条顺序指令的地址。
- 对于顺序指令:`PC ← PC + 4`。
2. **ID(Instruction Decode,指令译码阶段)**
- **功能**:对取出的指令进行译码,读取寄存器的操作数,生成控制信号。
- 具体操作
- `ID/EX.A ← Regs[IF/ID.IR[rs]]`:从寄存器堆读取操作数 `rs`。
- `ID/EX.B ← Regs[IF/ID.IR[rt]]`:从寄存器堆读取操作数 `rt`。
- `ID/EX.NPC ← IF/ID.NPC`:将下一条指令的地址传递到下一个阶段。
- `ID/EX.Imm ← (IF/ID.IR[15..0])`:对立即数字段扩展为32位。
- **分支指令**:下一跳地址计算、分支条件检查等。
3. **EX(Execute,执行阶段)**
- **功能**:执行指令的运算或地址计算。
- ALU指令
- `EX/MEM.ALUo ← ID/EX.A func ID/EX.B`:执行算术逻辑运算,将结果传递到下一阶段。
- Load/Store指令
- `EX/MEM.ALUo ← ID/EX.A + ID/EX.Imm`:计算内存地址。
- 分支指令
- `EX/MEM.cond ← (ID/EX.A == 0)`:判断条件是否成立。
4. **MEM(Memory Access,访存阶段)**
- **功能**:对内存进行读写操作。
- 具体操作
- **Load指令**:`MEM/WB.LMD ← Mem[EX/MEM.ALUo]`,从内存读取数据。
- **Store指令**:`Mem[EX/MEM.ALUo] ← EX/MEM.B`,将寄存器的值存入内存。
- 将指令传递到下一个阶段:`MEM/WB.IR ← EX/MEM.IR`。
5. **WB(Write Back,写回阶段)**
- **功能**:将结果写回寄存器。
- 具体操作
- `Regs[MEM/WB.IR[rd]] ← MEM/WB.ALUo`:将运算结果写入目标寄存器。
- 对于Load指令:`Regs[MEM/WB.IR[rt]] ← MEM/WB.LMD`,将从内存中读取的数据写回寄存器。
**3.5向量处理机**
为了充分发挥流水线的效率,实现高性能计算,有的流水线处理机设置了向量数据表示和相应的向量指令,这种处理机称为向量处理机。
**3.5.1向量处理方式**
1. 横向(水平处理方式)

2. 纵向(垂直处理方式):按列的方式从上到下纵向


3. 纵横(分组处理方式)
**3.5.2向量处理机的结构**
**3.5.3向量处理机性能的方法**
**3.5.4向量处理机的性能评价**
# 第4章指令集并行
在流水线的基础上进一步拓展,开发出更多的指令集并行(ILP)性。
开发ILP的方法主要有:
+ 基于硬件的动态开发方法
+ 基于软件的静态开发方法

克服的限制:
+ 保持相关,但避免发生冲突
+ 通过代码变换,消除相关
+ 相关是程序固有的一种属性,它反映了程序中指令之间的相互依赖关系。而具体的一次相关是否会导致实际冲突以及该冲突会带来多长的停顿,则是流水线的属性。

对于正确地执行程序来说,必须保持的最关键的两个属性是数据流和异常行为。

不仅需要保持数据相关性,还需要保持控制相关性。

**4.2指令的动态调度**
在程序执行过程中,依靠专门硬件对代码进行调度。
**4.2.1动态调度的基本思想**
因为简单流水线的指令都是按程序顺序流水和按序执行的。一旦某条指令被停顿了,后续的指令都会停止前进。**所以:检测结构冲突,等待数据冲突小时。只要检测到没有结构冲突,就可以让指令流出。并且流水后的指令一旦其操作数就绪就可以立即执行,这就是乱序执行。**


**4.2.2Tomasulo算法**
核心思想:
+ 记录和检测指令相关,操作数一旦就绪就立即执行,把发生RAW冲突的可能性减小到最少。
+ 通过寄存器换名来消除WAR冲突和WAW冲。
+ IBM 360/91之所以会采用Tomasulo算法,是基于以下几个方面的考虑:IBM360/91的设计目标是基于整个360系列的统一的指令系统和编译器来实现高性能,而不是设计和利用专用的编译器来提高性能。这样就需要更多地依赖于硬件
+ IBM360体系结构只有4个双精度浮点寄存器,限制了编译器调度的有效性
+ 360/91的访存时间和浮点计算时间都很长。
**例子:**
假设有两条指令,分别是**乘法(MUL)** 和 **加法(ADD)**,它们需要处理一些寄存器中的数据。为了简化起见,我们设有寄存器F0、F2和F4。
- **MUL**指令需要两个操作数:F2和F4(这两个寄存器已经有数据)。
- **ADD**指令需要三个操作数:F0、F2和F4(这三个寄存器中的数据要被加起来)。
操作步骤
我们通过图4.2中的几个步骤来讲解具体是如何处理这些依赖关系的:
(a) **MUL指令进入保留站Mu1**
首先,**MUL**指令流入一个叫做保留站Mu1的地方(这是一个等待执行的缓冲区)。此时,**MUL**指令所需要的两个操作数——F2和F4中的数据已经准备好了,因此它们会直接从寄存器中取出并送入Mu1保留站。
同时,**MUL**的结果将写入F0寄存器。所以,为了让系统知道,未来F0的值将由Mu1来产生,我们将F0对应的寄存器状态表(Q表)标记为**Mult1**,表示F0的值会由Mu1提供。
(b) **ADD指令进入保留站Add1**
接下来,**ADD**指令流入另一个保留站Add1,它需要三个操作数:F0、F2和F4。F2和F4已经就绪,可以从寄存器中直接取出;但F0的值还没准备好——它需要等待**MUL**指令执行完毕。
于是,ADD指令并不会马上执行,它会等待**MUL**指令的结果。这时,ADD指令把F0的操作数标记为它的提供者是Mu1(即F0的值将由Mu1提供)。同时,ADD指令将自己的结果写回到F2寄存器,所以它会在Q表中标记F2的提供者为**Add1**,表示F2的值将由Add1提供。
(c) **MUL指令完成计算**
当**MUL**指令完成计算,得到了结果(假设为e),它会将计算结果广播到总线。所有等待这个结果的指令(例如ADD指令)会自动接收到这个结果。
(d) **ADD指令执行**
当**ADD**指令收到**MUL**指令的结果(e)之后,F0的数据就已经准备好了,于是ADD指令可以立即开始执行,计算并写回结果到F2寄存器。
总结
- **Tomasulo算法**通过使用保留站和寄存器状态表(Q表)来动态调度指令,解决了指令间的数据依赖。
- 当指令需要的数据尚未准备好时,它们会等待,而不是阻塞其他指令执行。
- 当数据准备好后,依赖于该数据的指令能够立即继续执行。
后面的案例学习参考了这个老师的视频
[计算机系统结构4.1 Tomasulo算法_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1Cr4y1H7gA/?spm_id_from=333.337.search-card.all.click)
**4.3动态分支预测技术**
在第3章中介绍过几种静态处理分支指令的基本方法,如预测成功和延迟分支。在这些方法中所进行的操作是预先定好的,与分支的实际执行情况无关。**本节论述用硬件动态进行分支处理的方法。这些方法是在程序运行时根据分支指令过去的表现来预测其将来的行为。如果分支行为发生了变化,预测结果也跟着改变,因此有更好的预测准确度和适应性。**
分支预测的有效性不仅取决于其准确性,而且与预测正确和不正确两种情况下的分支开销都有密切关系。这些分支开销是由流水线的结构、预测的方法和预测错误时的恢复策略等诸因素决定的。
采用这些动态分支预测技术的目的有两个:预测分支是否成功和尽快找到分支目标地址(或指令),从而避免控制相关造成流水线停顿。
在这些方法中需要解决以下两个关键问题:如何记录分支的历史信息,以及如何根据这些信息来预测分支的去向(甚至取到指令)。
### **4.3.1采用分支历史表(BHT)**
用BHT来记录分支指令最近一次或几次的执行情况(成功或不成功)。
**2位的BHT:**
状态表和状态转换规则
- **00**: 预测分支不成功。
- **01**: 预测分支不成功(但是有可能会转向成功)。
- **10**: 预测分支成功(但还可以转向不成功)。
- **11**: 预测分支成功。
当分支指令实际执行的结果与预测结果一致时,状态不会改变;当预测错误时,状态会发生转变。
状态转换机制
- **状态转换的条件**:只有在 **连续两次预测错误** 时,才会改变对分支去向的预测。
- 预测错误的情况
:
- 如果当前状态是 `11`(预测成功),但实际分支指令结果为 **不成功**,则状态转变为 `10`(预测不成功)。
- 如果当前状态是 `00`(预测不成功),但实际分支指令结果为 **成功**,则状态转变为 `01`(预测不成功,但可能转为成功)。

**4.3.2采用分支目标缓冲器BTB**
因为BHT方法是在ID段对BHT进行访问,所以在ID段的末尾能够获得分支目标地址(在ID段计算出)、顺序下一条指令地址(在IF段计算出)以及预测的结果。如果再提前一拍(在IF段)就知道这些信息,那么分支开销就可以减少为0。
可以把BTB看做是用专门的硬件实现的一张表格。

当采用BTB后,在流水线各个阶段所进行的相关操作见图4.8所示。由于BTB中存放的是执行过的成功分支指令的地址,所以如果当前指令的地址与BTB中的第一字段匹配,那么就将该匹配项中第二个字段中的地址送给PC寄存器,从分支目标处开始取指令。如果预测正确,则不会有任何分支延迟。如果预测错误或者在BTB中没有匹配的项,则会有至少两个时钟周期的开销。因为这时需要更新BTB中的项,这要花费一个时钟周期。而且一般来说,当对BTB中的项进行修改时需要停止取指令,所以取新的指令又要花费另一个时钟周期。
**例子:**
假设有如下的程序:BEQ R1, R2, label ; 如果 R1 == R2,跳转到 label ADD R3, R4, R5 ; 如果不跳转,执行 ADD label: SUB R6, R7, R8 ; label 位置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
1. **第一次执行**:如果 `BEQ` 条件满足,分支会跳转到 `label`,并且 BTB 会记录下 `BEQ` 指令的目标地址(即 `label` 的地址)。这时,`PC` 会跳转到 `label`。
2. **下一次执行**:如果 **预测失败**,意味着分支指令实际没有跳转(比如 `R1 != R2`),这时:
- **预测错误**:原本预测分支成功,但实际未跳转。
- **更新 BTB**:在这种情况下,**BTB 中应该更新为顺序指令的地址**,即 `ADD` 指令的地址,而不是 `label` 地址。因为分支失败,程序会继续执行顺序的下一条指令——`ADD`。
3. **更新后的流程**:
- 当分支指令(如 `BEQ`)预测失败时,系统会停止并更新 BTB,将 **顺序执行的下一条指令地址**(在这个例子中是 `ADD` 的地址)存入 BTB。
- **取指令**:由于预测失败,指令取指环节会停下来,需要从新的 `PC` 地址(即顺序指令的地址)重新取指令。

### **4.3.3基于硬件的前瞻执行**
前瞻执行(speculation)能很好地解决控制相关的问题,它对分支指令的结果进行猜测,并假设这个猜测总是对的,然后按这个猜测结果继续取、流出和执行后续的指令只是执行指令的结果不是写回到寄存器或存储器,而是放到一个称为ROB(ReOrderBuffer)的缓冲器中。等到相应的指令得到“确认”(commit)(即确实是应该执行的)后才将结果写入寄存器或存储器。之所以要这样,是为了在猜测错误的情况下能够恢复原来的现场(即没有进行不可恢复的写操作)。
基于硬件的前瞻执行是把3种思想结合在了一起:
+ 动态分支预测。用来选择后续执行的指令。
+ 在控制相关的结果尚未出来之前,前瞻地执行后续指令
+ 用动态调度对基本块的各种组合进行跨基本块的调度,
前瞻执行(**Speculative Execution**)是一种优化技术,它允许CPU在不确定的情况下先行执行指令,以提高流水线的吞吐率。**Tomasulo算法**原本通过乱序执行来优化指令流水线,但它并没有处理分支指令的情况。而前瞻执行扩展了Tomasulo算法,使得即便遇到分支指令,也可以提前执行分支路径上的指令,提高性能。
你提到的例子中描述的是 **Tomasulo算法的扩展**,包括引入了两个新阶段:**“写结果”**(Write Result)和 **“指令确认”**(Instruction Commit),来支持前瞻执行。让我们逐步解释这个过程。
** 原始的Tomasulo算法:**
1. **写结果阶段**(Write Result):在这个阶段,指令的执行结果会写入 **ROB(Reorder Buffer)** 中,并通过 **CDB(Common Data Bus)** 在不同指令之间传递结果。结果可以供后续指令使用。执行结果已经产生,但指令的 "完成" 仍然没有确认。
2. **指令完成**:这时,指令才被标记为完成,更新寄存器或存储器的值,并将指令从ROB中移除。
**前瞻执行扩展:**
前瞻执行在Tomasulo算法的基础上进行了扩展,分成了两个阶段来更好地处理分支指令:
1. **写结果阶段**(Write Result):
- 当指令执行完并产生结果时,这个结果 **先被写入ROB**,但指令并不立即“完成”,而是继续保持在ROB中。
- 结果通过 **CDB** 传递给其他依赖该结果的指令,这些指令继续执行。
- 即使当前分支指令的结果尚不确定,**系统仍然允许继续执行**,即使分支判断结果可能会改变。这个过程就叫“前瞻执行”,CPU会**猜测**分支指令的结果,提前执行后续指令,假设分支会跳转到某个地址。
2. **指令确认阶段**(Instruction Commit):
- 在这个阶段,CPU会确认前瞻执行的结果是否正确。具体来说,当**分支指令的执行结果**出来时,CPU检查分支是否按照预测的方向跳转。
- 如果分支预测**正确**,那么之前在ROB中写入的结果会被提交到 **寄存器或内存**(即把前瞻执行的结果**确认**并写回系统)。
- 如果分支预测**错误**,之前执行的指令会被**撤销**,并且 **不提交**之前的结果。这时,CPU会丢弃前瞻执行的指令结果,重新从正确的路径开始执行,避免影响程序的正确性。
**前瞻执行的关键特点**:
1. **乱序执行**:前瞻执行允许指令按照程序顺序的**假设路径**乱序执行,即便分支指令的真实结果尚未确定。
2. **按程序顺序确认**:虽然指令可以乱序执行,但它们的结果必须按程序顺序进行确认。这确保了程序的一致性,即结果只能在确定了分支的真实执行路径后才能被确认。
3. **不可恢复操作的限制**:在指令被确认之前,系统不会进行**不可恢复的操作**,例如修改计算机状态或触发异常。只有在确认的情况下,才能更新寄存器和内存状态,以避免错误的操作对程序执行产生不可逆影响。
**例子:**
假设我们有以下代码:
- 初始预测:
- BEQ 被预测为跳转到
label。 - 在没有分支预测的情况下,前瞻执行会假设 BEQ 为“跳转”,并提前执行跳转后的指令
SUB。
- BEQ 被预测为跳转到
- 执行前瞻:
- 在 写结果阶段,指令
BEQ的结果(跳转到label)被写入到 ROB 中,系统继续执行后续指令(即SUB),并传递结果到需要它的指令。
- 在 写结果阶段,指令
- 指令确认阶段:
- 在 指令确认阶段,BEQ 计算出分支结果。假设分支的结果为 不跳转,那么之前“跳转”的预测是错误的。
- 系统会 丢弃之前
SUB指令的执行结果,因为它是在错误的分支路径上执行的。 - 然后,从正确的路径(即顺序执行
ADD)开始重新执行,直到程序正确执行。
总结:
前瞻执行通过 乱序执行和分支预测来提升性能,但它要求:
- 乱序执行时,不影响程序的正确性,确保在确认之前不会做出不可恢复的操作。
- 分支确认:只有当分支的真实结果确认后,才会正式提交之前的执行结果。如果分支预测错误,前瞻执行的结果会被撤销,并重新执行正确的路径。
通过这些机制,前瞻执行使得 CPU 可以在遇到分支指令时提前执行,从而减少等待时间,提高程序的执行效率。
4.4 多指令流出技术
4.4.1基于静态调度的多流出技术
4.4.2基于动态调度的多流出技术
4.4.3超长指令字技术
4.4.4多流出处理器受到的限制
4.5循环展开和指令调度
4.5.1循环展开和指令调度的基本方法
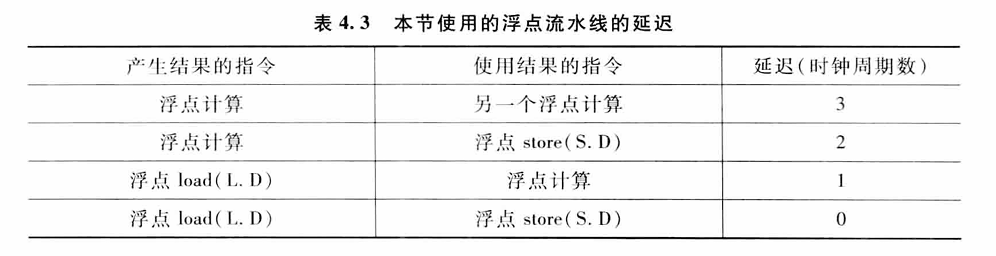
例4.6










第5章 存储系统
5.1.2 存储系统的性能参数




5.1.4 存储层次的4个问题
- 把一个块(页)调入高一层(靠近CPU)存储器时,可以放到哪些位置上。(影响规则)
- 当所要访问的块(页)在高一层存储器中时,如何找到该快。(查找算法)
- 当发生不命中而且高一层存储器已经满时,应替换哪一块。(替换算法)
- 当进行访问时,应进行哪些操作。(写策略)
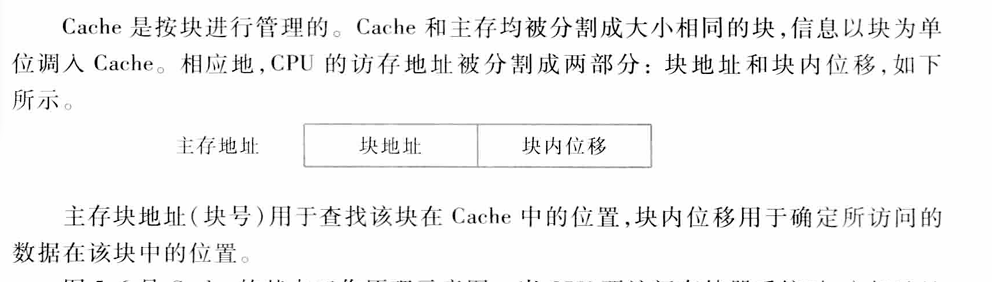
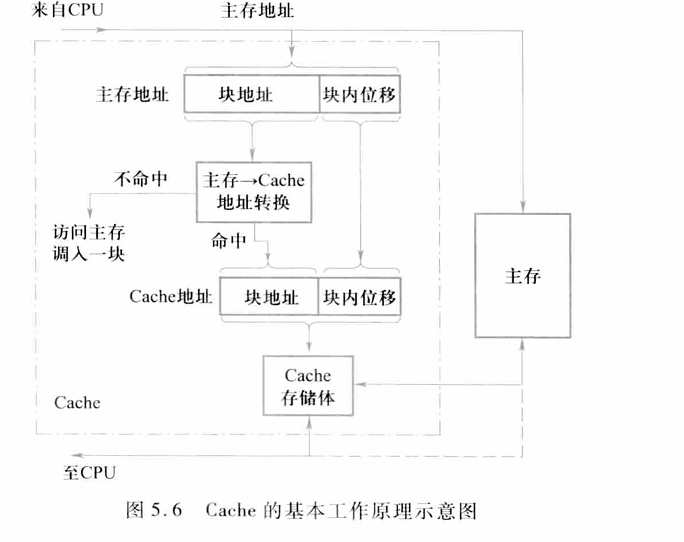
5.2Cache基本知识
5.2.2映像规则
- 全相联映射
- 直接映像
- 组相连映像
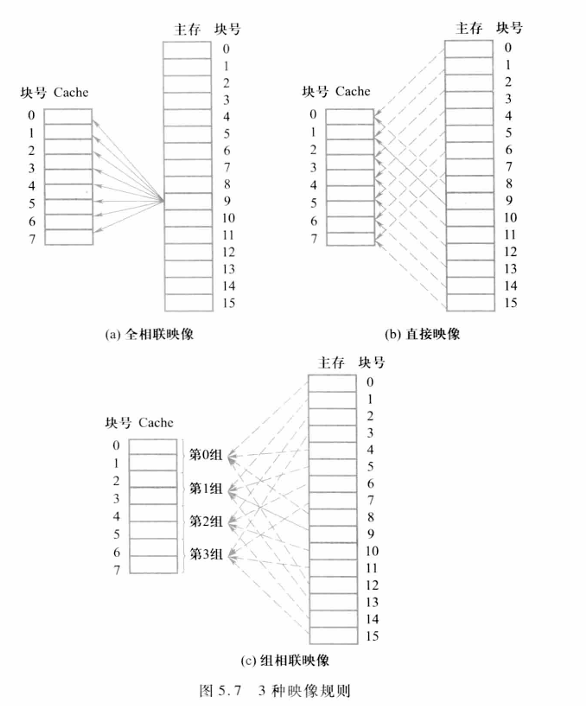


相联度越高(即n的值越大),Cache空间的利用率就越高,块冲突概率就越低,因而Cache的不命中率就越低。但是实现会越复杂,所以绝大多数计算机都采用直接映像、2组相联或4路组相联。
5.2.3查找方法
当CPU访问存储器中的某个单元时,如何在Cache中找到包含该地址的块(如果有的话)?这是通过查找目录表来实现的。Cache中设有一个目录表,每一个Cache块在该表中都有唯一的一项,用于指出当前该块中存放的信息是哪个主存块的(一般有多个主存块映像到该Cache块)。它实际上是记录了该主存块的块地址的高位部分,称为标识(tag)。每个主存块能唯一地由其标识来确定。

由于目录表中存放的是标识,所以存放目录表的存储器又称为标识存储器。目录表中给每一项设置一个有效位,用于指出Cache中的块是否包含有效信息。例如,用该位为“1”表示Cache中相应块所包含的信息有效。当一个主存块被调人Cache中某一个块位置时,它的标识就被填入目录表中与该Cache块相对应的项中,并将其有效位置“1”。根据映像规则不同,一个主存块可能映像到Cache中的一个或多个Cache 块位置。为便于讨论,将之称为候选位置。当CPU访问该主存块时,必须且只需查找它的候选位置的目录表项(标识)。如果有标识匹配(即相同)的项,且其有效位为“1”则它所对应的Cache块即是所要找的块。为了保证速度,对各候选位置的标识的检查应并行进行。
根据映像规则不同,一个主存块可能映像到Cache中的一个或多个Cache块位置,将之称为候选位置。
无论是直接映像还是组相联,查找时只需比较标识,索引无须参加比较。这是因为索引已被用来选择要查找的组(或块),而所有索引相同且只有索引相同的块才被映像到该组(块)中,所以该组中各块的索引一定与本次访存的索引相同。如果Cache的容量不变,提高相联度会增加每一组中的块数,从而会减少索引的位数和增加标识的位数。在全相联的情况下,索引的位数为0,块地址就是标识。
不同映像方式下的查找过程
- 直接映像(Direct-Mapped Cache):
在直接映像方式下,每个主存块只能映射到 Cache 中 一个特定的 Cache 块。也就是说,主存地址中的 索引部分 用于确定 Cache 中的某个位置,标识部分 用于与该 Cache 块中的内容进行比较,验证该块是否是我们需要的块。
查找过程:
- 索引:从主存地址中提取出来的索引部分,用于在 Cache 中选择一个具体的块。
- 标识:Cache 中每个块都存储了一个标识,表示该 Cache 块存储的是主存中的哪个块。如果这个标识与访问请求中的标识相匹配,并且有效位为 1,则表示命中。
- 块内偏移:一旦命中,偏移部分帮助定位到 Cache 块内具体的数据。
- 组相联映像(Set-Associative Cache):
在组相联映像中,Cache 被划分为多个 组,每组中有多个块。每个主存块可以映射到 多个候选位置,即某个主存块可以映射到 Cache 中的多个块(在同一个组内)。为了提高查找的效率,所有候选位置的标识会并行进行比较,如果有一个匹配,就表示命中。
查找过程:
- 索引:从主存地址中提取出来的索引部分,用来选择具体的 组(Set),而不是直接选择一个块。
- 标识:在该组内的每个 Cache 块中都会存储一个标识(Tag),当有多个候选位置时,所有候选位置的标识会并行进行比较,看是否有匹配的项。
- 块内偏移:与直接映像方式相同,一旦命中,偏移部分帮助定位到 Cache 块内具体的数据。
- 全相联映像(Fully-Associative Cache):
在全相联映像方式下,主存块可以映射到 Cache 中的任何位置,没有固定的映像位置。也就是说,主存地址的 索引部分 不参与 Cache 查找,而是整个主存地址的 标识部分 会用来和 Cache 中的所有块进行比较。
查找过程:
- 标识:将主存地址中的标识部分与 Cache 中所有块的标识并行比较,找到匹配的 Cache 块。
- 块内偏移:与前两种方式相同,命中后,通过块内偏移确定 Cache 中具体的数据。
总结就是:标识用来判断是否命中,索引用来定位Cache组号。所以在扩大相联度的情况下,标识位会扩大,索引位会减少,因为一个组可以划分更多的Cache块。
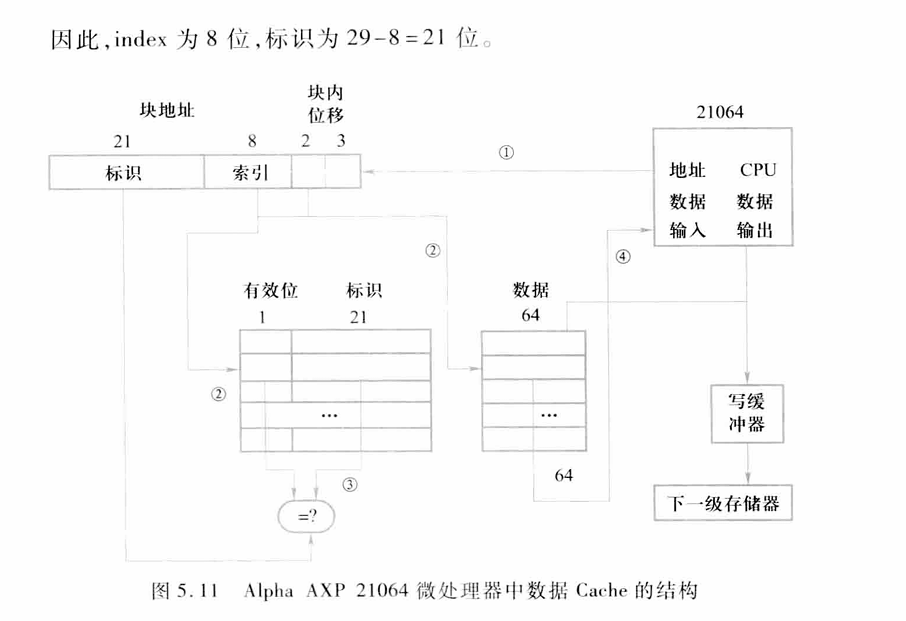
5.2.4 Cache的工作过程


5.2.5替换算法
随机法:随机地选择被替换的块。
先进先出法:FIFO
最近最少使用法:LRU
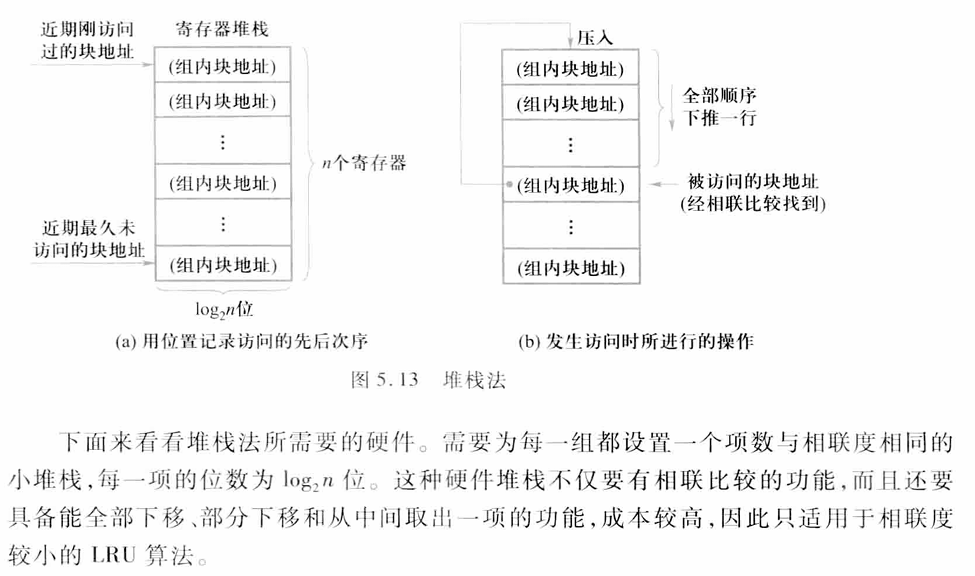
LRU的硬件实现:
堆栈法
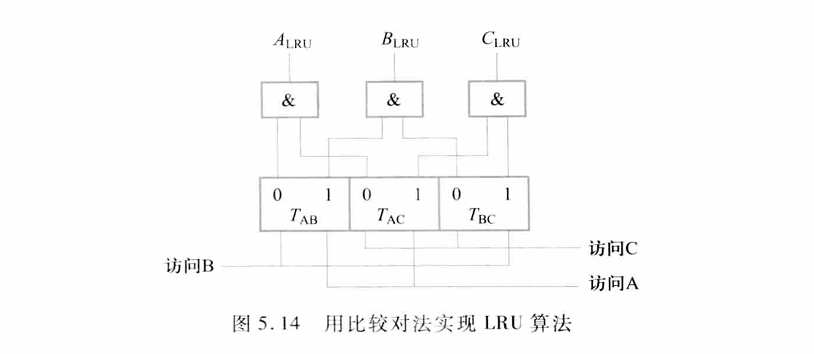
比较对法:

5.2.6写策略

5.2.7Cache性能分析

5.3.1三种类型的不命中


5.3.2增加Cache块大小
5.3.3增加Cache的容量
5.3.4提高相联度
5.3.5伪相联Cache
5.3.6硬件预取
5.3.7编译器控制的预取
5.3.8编译优化
5.3.9“牺牲”Cache
5.4减少Cache不命中开销
5.4.1采用两级Cache
5.4.2读不命中优先于写
5.4.3写缓冲合并
5.4.4请求字处理技术
5.4.5非阻塞Cache技术
5.5减少命中时间
5.5.1容量小、结构简单的Cache
5.5.2虚拟Cache
5.5.3Cache访问流水化
5.5.4踪迹Cache
5.5.5Cache优化技术总结
5.6并行主存系统
5.7虚拟存储器
5.7.2快速地址转换技术



TLB 结构和功能简介
TLB 是一个存储器,它存储了虚拟地址到物理地址的映射(即页表项)。每次 CPU 需要从内存中读取或写入数据时,它首先会将虚拟地址转换成物理地址。这个过程通常需要查阅页表,但是查页表的速度相对较慢,因此通过 TLB 来缓存最近使用的虚拟地址到物理地址的映射,以加速转换过程。
图中提到的 40个项 和 全相联映像,意味着 TLB 中有 40 个条目,每个条目保存了虚拟页地址到物理页地址的映射,且所有条目是平等的,不需要通过索引定位特定项,而是需要遍历整个 TLB 来查找匹配的条目。
TLB 地址转换过程解析
- 步骤①:虚拟地址送往标识
- 在 CPU 要访问一个数据时,虚拟地址会被送到 TLB 中。
- 虚拟地址会被拆分成多个部分,其中一部分用来和 TLB 中的标识进行比较。
- 标识是用来判断虚拟地址是否已经有对应的物理地址映射的。
- 步骤②:标识匹配比较
- TLB 中的每个项都包含一个 标识,即虚拟页的标识符。虚拟地址中的高位部分(即虚拟页号)会与 TLB 中的标识部分进行比较。
- 只有标识为“1”(有效位有效)的项才会参与匹配。
- 如果虚拟地址中的标识和 TLB 中某一项的标识匹配,就说明该虚拟地址在 TLB 中找到了对应的物理地址映射,即 TLB 命中。
- 步骤③:物理地址选出
- 如果 TLB 命中,意味着 TLB 中的某一项包含了该虚拟地址的物理地址映射。
- 然后,多路选择器(MUX) 会从 TLB 中选出匹配项的物理地址。
- 每个项中都存储着一个物理页的地址,以及与该页相关联的其他信息(如存储保护信息等)。
- 步骤④:拼接物理地址
- 物理页地址和虚拟地址中的 页内位移(即虚拟地址中的低位部分)结合,得到完整的物理地址。
- 通过这种方式,CPU 得到的物理地址就可以直接用于访问内存。
第6章 输入/输出系统
第7章 互联网络
第8章 多处理机
第9章 集群系统
第10章 多核系统结构与编程
多核处理器又称单芯片多处理器(CMP),是指在单个芯片内集成两个或多个处理器。其中,芯片内的每个处理器称作“核”。
10.1.1 功耗与散热问题
CPU的发热量主要取决于处理器的密度和时钟频率,与这两者是成正比关系,受功率和散热方法的限制,时钟频率不能无限制地增加。所以Intel处理器的最高主频在达到了3.8GHz以后,就没有继续往上推进了,而是向多核发展。
10.2.1多核的组织架构
多核处理器的组织架构主要包括片上核心处理器的个数、Cache的级数、共享Cache的容量和内部互联结构。
共享Cache的好处:

10.3基于多核的并行程序设计
目前几种最重要的并行编程模型是数据并行(dataparalel)模型、消息传递(mes-sage passing)模型和共享变量(sharedvariable)模型。数据并行模型的编程级别比较高,编程相对简单,但它仅适用于数据并行问题;消息传递模型的编程级别相对较低,但该模型可以有更广泛的应用范围;共享变量模型则采用多线程的方式,非常适合对称式共享存储器多处机系统和多核处理器体系结构。
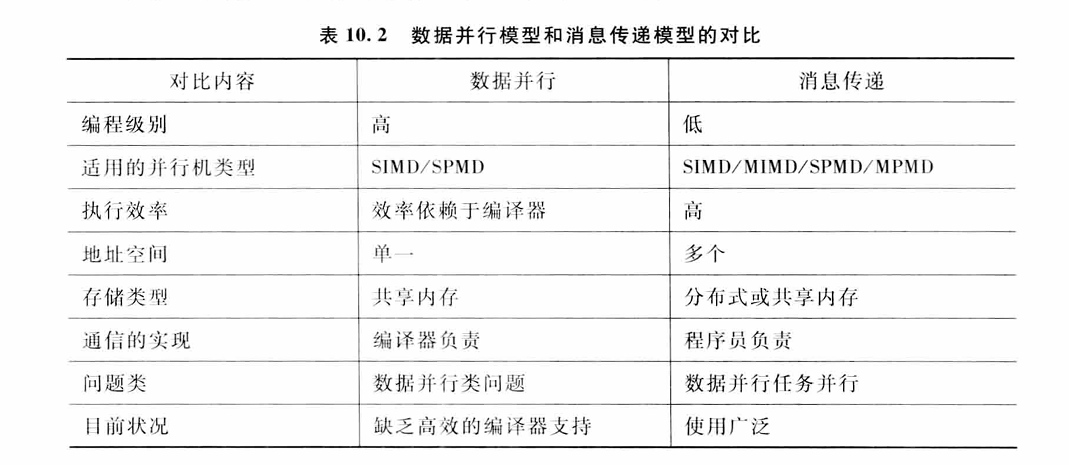
10.3.3并行算法
根据进程之间的依赖关系,可以将并行算法分为同步并行算法(步调一致)、异步并行算法(步调、进展互不相同)和纯并行算法(各部分之间没有关系)

